# December Adventure 2024
Low-key code-based fun in December 2024.
The Advent of Code is cool, but a lot, and not everyone’s jam. The December Adventure is low key. The goal is to write a little bit of code every day in December. – eli.li/december-adventure
Microblog thread at post.lurk.org.
See also: December Adventure 2025.
# 1 One
I started searching through The Online Encyclopedia of Integer Sequences (OEIS) to find interesting things to make diagrams of the number 2025.
Probably can’t top
sum [n^3 | n <- [1..9]] = sum [1..9]^2 = 2025
for neatness, but maybe some other things will be interesting when drawn.
# 2 Two
# 2.1 Morning
I wrote 100 lines of C99 code (with no dependencies apart from libc),
to render a short video loop representing sum [1..9]^2 = 45^2.
I rendered larger, downscaling for antialiasing and encoding with ffmpeg.
# 2.2 Afternoon
Number of lattice paths from (0, 0) to (n, n) with steps (1, 0) and (0, 1), having k right turns. – oeis.org/A008459
When n = 10 and k = 2, the total count is 2025. Filled, they look like lots of copies of the letter L with different proportions.

SVG text generated with 25 lines of Haskell, converted to PNG with ImageMagick.
import Control.Applicative ((<$>))
import Control.Monad (forM_)
import Data.List (nub, sort, tails)
a008459 :: Int -> Int -> [[Bool]]
a008459 n k = nub . sort . filter ((k ==) . sum . map f . tails) . go $ (0, 0)
where
go (x, y) =
(if x < n then (True :) <$> go (x + 1, y) else if y == n then [[]] else []) ++
(if y < n then (False:) <$> go (x, y + 1) else if x == n then [[]] else [])
f (False:True:_) = 1
f _ = 0
main :: IO ()
main = do
putStrLn "<svg xmlns='http://www.w3.org/2000/svg' width='720' height='720'>"
putStrLn "<rect width='100%' height='100%' fill='white' stroke='none' />"
putStrLn "<g fill='black' stroke='none'>"
forM_ (a008459 10 2 `zip` [(x, y) | y <- [44,43..0], x <- [0..44]]) $ \(l, (x, y)) ->
putStrLn ("<path d='M " ++ show (25 + 15 * x + 10) ++ "," ++ show (25 + 15 * y + 10) ++
" l" ++ concatMap (\x -> if x then " -1,0" else " 0,-1") l ++ " 0,10 z' />")
putStrLn "</g>"
putStrLn "</svg>"
# 3 Three
# 3.1 Small Hours
A “nightrider” is like a chess knight that can move any distance in the 8 directions.
A toroidal board wraps around at the edges left/right top/bottom.
There are 2025 configurations of 9 mutually non-attacking nightriders on a 9x9 toroidal board. – oeis.org/A190393
Bright pixels are the pieces, dim pixels are attacked squares. Colour is based on the position of the piece on the board.

Excerpt from 120 lines of C99:
void recurse(int b, int n)
{
if (! b)
draw_board();
else
{
struct board undo = board;
for (int m = n; m < N * N; ++m)
if (! board.attacked[m / N][m % N])
{
add_piece(m / N, m % N, b);
recurse(b - 1, m + 1);
board = undo;
}
}
}
There seem to be only 37 equivalence classes under toroidal translations, which I calculated first with some extra code, and wondered why I didn’t match the OEIS…
# 3.2 Morning
Video sketch now at 125 lines of code, in colour, with added dependency libm.
Representing an additional decomposition of sum [1..9]^2
as a triangle of triangles.
I also sketched on paper some ideas for animating sum of cubes.
It’ll be a lot more effort to implement it,
but it should be a nice visual proof that
sum [1..k]^2 = sum [n^3 | n <-[1..k]], with k = 9 giving 2025.
# 3.3 Afternoon
There are 2025 words using 0, 1 and 2 which have length 7 and don’t appear 0000 or 1111. – oeis.org/A287898

(Click for full image.)
Made with 35 lines of Haskell outputing text, plus 15 lines of handcoded HTML and CSS to wrap it.
Screenshot from Firefox.
# 4 Four
I took a day off from 2025 diagrams. Worked on some music code instead:
-
cleaned up 4 compositions (proper start/end, overall volume at -23LUFS)
-
made progress cleaning on a 5th track
-
added sndfile backend to the main program
-
made returning nonzero from dsp callback mean “stop” (previously value was unused)
-
made it work on aarch64 (remove some x86_64 flags) - but tablet is not fast enough to synthesize all of it in realtime
-
put it all in a (private) repository for easy replication/backup, including the edit histories of 4 livecoded pieces that I want to fix into static “deadcode”
-
organized the wav files a bit more sensibly, separate folder for final vs outtakes/rehearsals/alt versions etc
-
started thinking about how to approach accompanying music videos
# 5 Five
# 5.1 Morning
more music making
-
finished cleaning the 5th track from yesterday
-
sequenced/shortened/deadcoded a previously live-coded take of a 6th track that I wasn’t 100% happy with
-
added a centralized album config.h with samplerate, sampletype, etc
-
experimented with 384kHz sample rate - overall not much difference - it’s nice to be sample-rate independent, thought some things (e.g. hilbert transformer) might be way off but pleasantly surprised
-
at 384kHz a few sounds on a couple of tracks are slightly better (e.g. a hard-sync oscillator and some hihats sound a bit clearer due to less aliasing in audible range). but my DAC is only running at 48kHz, so not surprising I can’t hear much difference.
-
went back to 48kHz for working on the final 3 tracks of the project as the 8x longer render times are a bit painful
# 5.2 Afternoon
more music making
-
rewrote another track, only 2 left to do now (the first one is long and will be tricky to sequence; the other is short and should be fairly easy)
-
switched sndfile writer to use CAF audio file format instead of WAV, as one of the other tracks is probably long enough to breach 2GB at 384kHz
-
took some benchmarks: on my desktop, 7 tracks almost 30mins total take 3mins CPU time to render at 48kHz, while my netbook is significantly slower than realtime. tablet is 25% faster than phone.
# 6 Six
Morning music.
-
did the remaining short track
-
wrapped some (very) long lines to a reasonable length
-
wc -L now reports longest line across the 8 finished tracks is 82 characters (not sure i can shorten them below 80 without annoying breaks)
-
compiled all the tracks into a single program binary with an argument for which track to play/render
# 7 Seven
# 7.1 Day
replaced libsndfile with custom wav writer.
replaced sdl2 audio with custom oss writer (16bit with dither, not sure how to do 24bit or float32 on linux).
went down the rabbit hole of removing dependency on libc: needed memset strlen atoi; and _start and lseek syscall for x8664 (other arch still to do) with other i/o syscalls copy/pasted from my DeeperDisco project (openat needed a mode argument for OCREAT). FILE code now uses fd instead.
started down the deeper hole of removing dependency on libm (frexp sqrt exp sin cos seem to work, log goes into an infinite loop for some arguments, atan2 untested…)
binary for album is less than 64kB, still missing cover art code.
# 7.2 Night
got the ARM 32bit build working:
-
needed to add -fomit-frame-pointer so I could use r7 register for syscalls
-
had no end of trouble (illegal instruction, segmentation fault, bus error, …) with
_startuntil I tried making it the first file at which point it worked fine - maybe old compiler is to blame -
needed to link libgcc for float double <–> int64 conversions.
optimized exp a bit: 6 terms of taylor series for 0 < x <1/2^8 with range reduction using frexp followed by squaring outside
got log terminating (6 iterations of newton’s method using exp after range rediction with frexp), still looking for a faster way…
# 8 Eight
more progress on music infrastructure
-
got Linux ARM 64bit build compiling, need to test and maybe fix some things
-
got Windows cross-builds working (x86_64 and i686), only realtime whole album play all mode so far (need to add WAV writer and better UI).
-
I have no way to test Windows ARM builds so not compiling them yet
-
vaguely thinking about Android, low priority
-
also considering non-Linux posix-y platforms, and other architectures for linux (even lower priority)
-
thinking a lot about optimisation - performance is a lot worse with my custom libm replacement. probably I don’t need 53 bits of precision everywhere, and probably I am recalculating some things every sample that could be cached and reused. need to see if I can make a faster sin() than my sincos() which also computes a cos() I don’t need. I should profile and see what the hot spots are…
-
still haven’t sequenced the long track, or found my artwork code, or made any videos…
# 9 Nine
# 9.1 Morning
my previous benchmark (before i started down the libm replacement rabbit hole) took 203 seconds to render the WIP album, on desktop
after today’s optimization effort, using libc and libm instead of my own code, it takes 138 seconds, almost 50% faster.
compiled on tablet is 65% faster, now all tracks render faster than realtime
compiled on phone is about the same speed, album renders slightly faster than its duration (on average), but 4 tracks are too heavy for individual realtime playback
compiled on netbook is 30% slower, for the 5 tracks i had previous benchmarks for - not sure what is going on there. the same 4 tracks are too heavy for realtime, and the album overall takes considerably longer to render than its duration
# 9.2 Evening
my laptop (pretty old, with Core 2 Duo 2.2GHz CPU) can run all the tracks in realtime if I use single precision instead of double precision, performance on phone improved too
need to check audio quality doesn’t suffer (I do still use double inside recursive filters, but chances are some time measurement things could get audibly quantized after a couple of minutes)
# 10 Ten
# 10.1 Morning
audio quality did suffer with single precision as I predicted
went through everything making the things that need it explicitly double precision
now quality is better than “everything single precision” and performance is better than “everything double precision”
benchmark:
prec\secs desktop laptop phone
double 140 2065 2368
single 117 700 1599
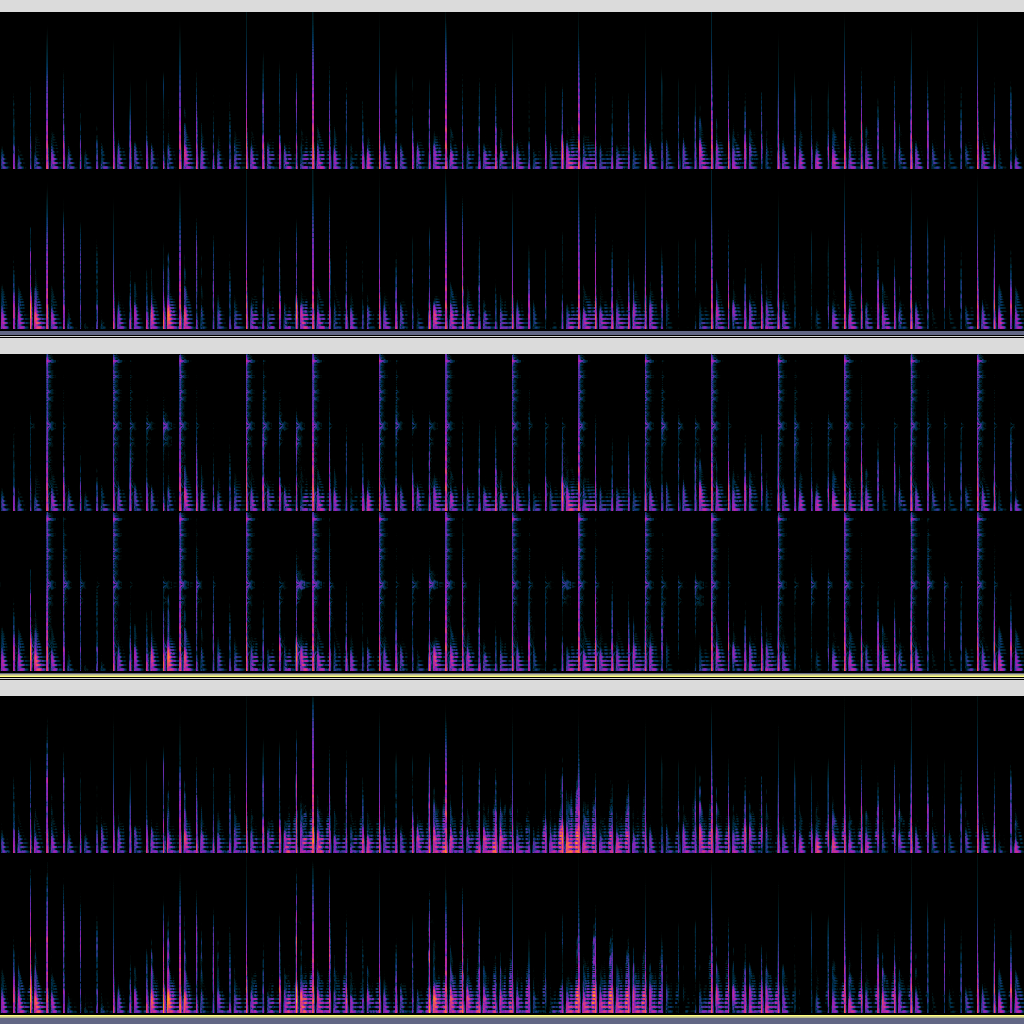
three stereo spectrograms log display from 1000-24000Hz at 48000Hz sample rate
top: double precision: all ok
middle: single precision: extra high frequency content due to quantization error
bottom: mixed precision (double where needed, single otherwise): seems better, but the other differences from double are a bit concerning…
# 10.2 Afternoon
so far on my goat farming i have:
sin + cos (range reduction using floating point data format, followed by cubic taylor polynomial, and double angle formula to undo the range reduction)
exp (range reduction to [0..1/256], then taylor series until it converges, followed by repeated squaring),
expm1 (if input in [-1..1] use exp’s taylor series omitting first 1 until it converges, otherwise use exp function implemented earlier and subtract 1)
rsqrt (reciprocal square root, using floating point magic number to get initial approximation for newton’s method)
sqrt (1 / reciprocal square root),
log (range reduction to [1/2..1], then inital approxmation based on taylor series for log(1+x) for newton’s method using exp(), undoing range reduction by adding a multiple of log(2), which constant pre-computed elsewhere).
top costs in profile:
seconds calls seconds/call function
402.34 23749919550 .0000000169406889 sincos
199.12 14767927465 .0000000134832731 rsqrt
180.19 11115474228 .0000000162107343 exp
107.80 7706374128 .0000000139884202 delread4
82.14 5620077084 .0000000146154578 compress_
68.03 26098736541 .0000000026066395 frexp
62.43 19197826612 .0000000032519306 biquad
# 11 Eleven
experimenting with truncating Taylor series in Chebyshev basis instead of monomial basis. better worst case error on interval [-1,1].
not having Matlab for Chebfun, and not seeing signs about Octave compatibility, I implemented in Haskell with exact rational arithmetic converting to double precision only for final output as C code, wrote Gauss-Jordan elimination following textbook, wrote and memoized coefficient calculation following oeis.
also did conversion of polynomial to Padé approximant, but the error goes up rapidly away from the center. did not find a way to combine Chebyshev with Padé, so probably not as useful.
my sincos in previous toot is accurate to 40 bits or so. Chebyshev thing gets close to limit of double precision. speed to be evaluated. there’s some branching to do with sin vs cos vs negation, using translated intervals n pi /2 +- pi/4.
# 12 Twelve
speed of chebyshev basis truncated series sin+cos on -1..1 is significantly better than my previous sincos implementation (range reduction, cubic approx, angle doubling), plus more accurate.
implemented sinh and cosh on -1..1 in a similar way, and tanh on -1..1 as sinh/cosh. outside -1..1 i use tanh(2t) = 2 tanh(t) / (1 + tanh(t)^2). accuracy seems pretty good.
haven’t checked the speed of my new tanh yet, in any case for most of the non-critical “slight soft clipping” parts i’m using a gross but fast approximation from musicdsp website: x (27 + x^2) / (27 + 9 x^2) (with hard clipping of input outside -3..3)
meanwhile started doing new benchmarks using libm with valgrind/callgrind, as gprof didn’t pick up library calls. went out for lunch, did some shopping, and it’s still only 1/2 way through. planning to merge the output files with cg_merge and inspect with kcachegrind
then I need to do a comparative benchmark using my custom code, which is likely to take even longer. i can run them in parallel i guess…
# 13 Thirteen
# 13.1 Morning
raw timing results of 384kHz render on desktop (without profiling):
using libm: 18m00s, of which 41% in libm custom maths: 23m32s (30% slower total)
combining the percentages makes me conclude my maths code is 75% slower than libm.
profile results are confusing because they’re given in percentages but the total time is different. for example my custom sin+cos is about the same speed as libm:
with libm:
sincos, sin, cos total ~23 billion calls (32 billion results) and 28% of runtime, which is about 300 seconds
custom maths:
sin_poly1, cos_poly1 total ~33 billion calls (33 billion results) and 9.2% of runtime, but the surrounding branching range reduction stuff takes another 12%, totalling 21% of runtime, which is also about 300 seconds
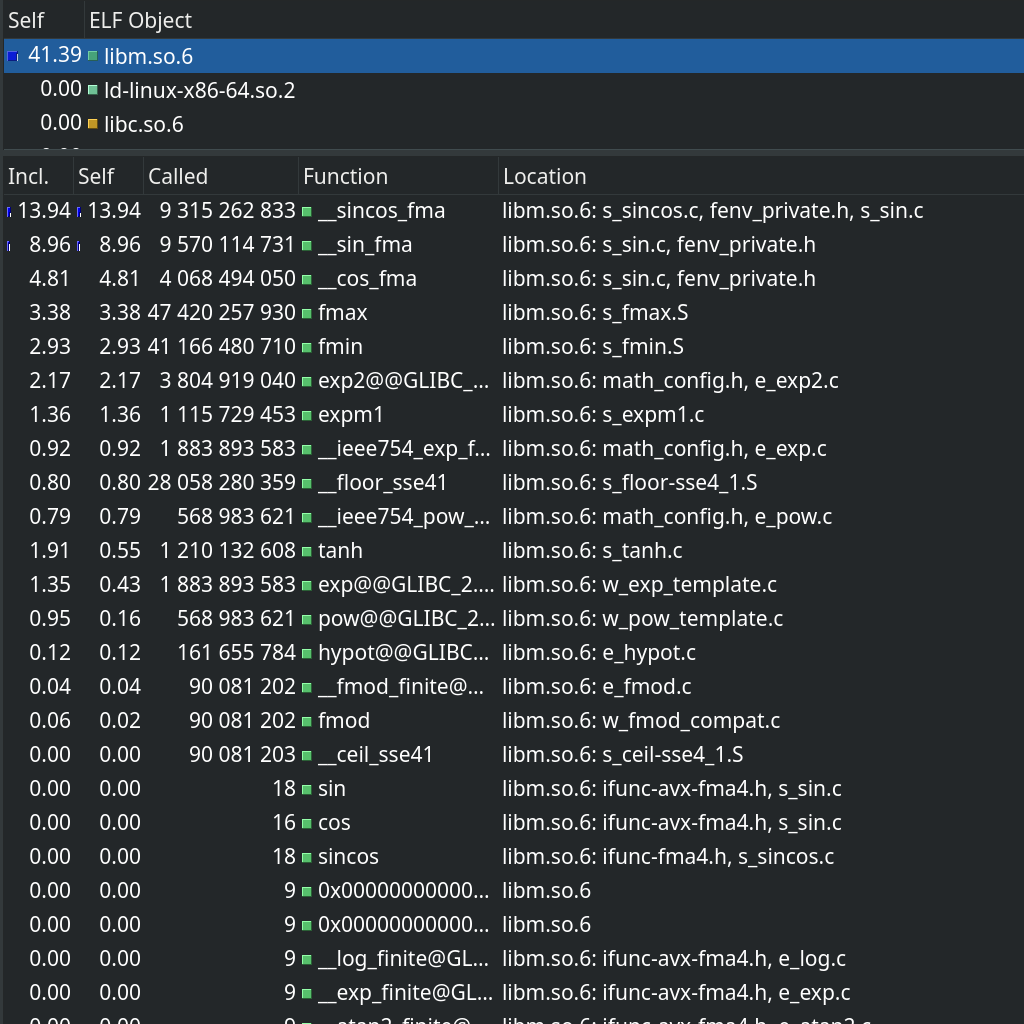
screenshot of kcachegrind showing flat profile for ELF objects
41.39% libm.so.6
functions within libm sorted by Self percent
13.94% __sincos_fma
8.96% __sin_fma
4.81% __cos_fma
3.38% fmax
2.93% fmin
2.17% exp2
1.36% expm1
...
table also shows called count (in the billions), and location (source code filename within libm.so.6)
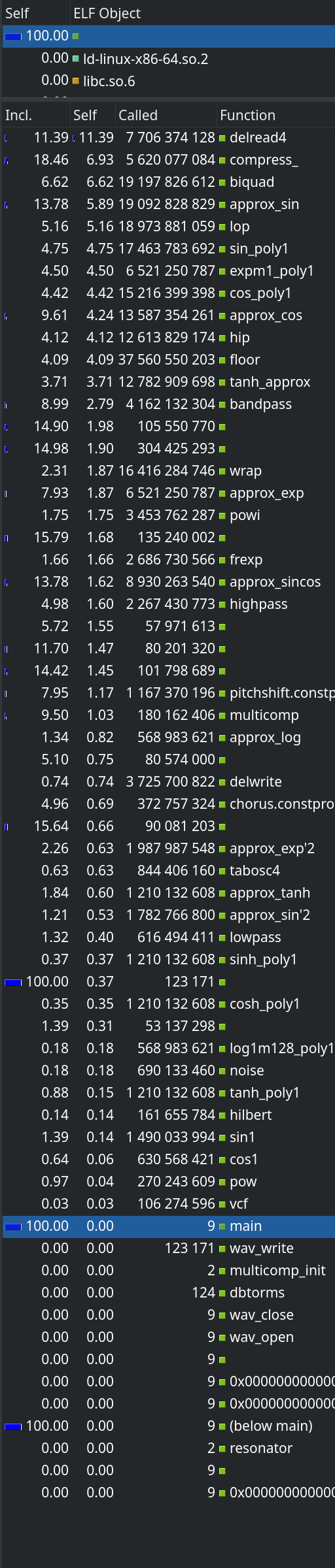
redacted screenshot of kcachegrind profile, 100% in main program (no libm)
functions sorted by Self percent
11.39% delread4
6.93% compress_
6.62% biquad
5.89% approx_sin
5.16% lop
4.75% sin_poly1
4.50% expm1_poly1
4.42% cos_poly1
4.24% approx_cos
4.12% hip
4.09% floor
3.71% tanh_approx
2.79% bandpass
...
table also shows called count (in the billions)
# 13.2 Afternoon
looked into extracting raw executable code from .o so i could compress it, as EXE is a little larger than my target. it worked to some extent but i forgot about .data and .bss sections and the needed relocation even with position independent code…
next idea: compile to a .dll/.so and LoadModule/dlopen it from memory after decompression, if that is possible. otherwise resort to a third party exe packer or just live with bigger binary…
# 14 Fourteen
# 14.1 Morning
I instrumented the delay line code, to report minimum/maximum delay actuallly used in samples.
Used maximum delay at 384kHz to tune the size of some buffers. Rounded delay line sizes up to power of two, to make reading/writing more efficient. Discovered that long, double precision delay lines on my phone push struct size past some limit (32MB or so) and it segfaults before main() is entered.
Used minimum delay at 44.1kHz to think about block-based processing to increase efficiency. Conclusion: block size 32 should be safe everywhere except inside a chorus effect, which uses localized feedback only so not a problem (can reblock inside).
# 14.2 Afternoon
Implemented block based processing primitives. Converted one track to block based so far.
Spent hours debugging some significant differences in audio output of vector vs regular code, which turned out to be that the regular code had the output arguments of one sincos() call swapped vs the vector code. Now agrees to 150dB according to Audacity, nothing was wrong with the rest of the code
Conclusion: block size 32 is 7% faster for this track on my desktop.
Meanwhile started adding skeleton code for OpenGL to the Windows version, so far it opens a window and clears it, with a message box to click to exit.
Decided against trying to write my own EXE packer, too much to go wrong… UPX gets the Windows x86_64 EXE 93696 -> 38400 bytes. Also works for Linux, 53664 -> 26144 bytes (no graphics yet).
# 15 Fifteen
no coding today
benchmarked on phone: blocked is 13% faster benchmarked on tablet: blocked is 6% faster
# 16 Sixteen
back to 2025 visualization
finished video of visual proof that
(sum [1..n])2=sum [k3 | k<-[1..n]]
using the case k = 9.
so far in total (including previous days work) I guesstimate I put in about an hour of effort per second of output video.
thinking about adding a soundtrack later this week…
# 17 Seventeen
#TilingTuesday
Inspired by Cut-and-Project method for aperiodic tilings
I tried to implement it in GLSL but got something different. Still, quite happy with my hack to prevent glitchy lines appearing in unintended places (dFdx(v) - round(dFdx(v)).
Image is based on a 2D plane, rotated and offset into 4D space, slicing a 4D hypercube honeycomb.

non-repeating pattern of irregularly-shaped regions in yellow, red, blue and green, outlined in black. not really a tiling because there are too many different shapes.
# 18 Eighteen
got cut-and-project in GLSL almost working
spent hours trying to debug the glitches but didn’t solve it yet

aperiodic cut-and-project tiling based on 4D hypercubic lattice, with 6 kinds of parallelograms

similar to previous image, but some glitches are present (mainly partial green rectangles that shouldn’t be there)
it’d probably be much less computational work to generate the polygons on the cpu and rasterize with opengl, than to loop over nearby hypercube cells for every pixel. inefficiency factor depends on size of polygons and display resolution. my glsl experiment struggles at 1080p on amd rx 580 gpu, while the wasm thing i linked earlier has no issues animating on my tablet.
meanwhile animation is a bit jarring because the shapes pop into other orientations instantly. colouring using distance from cut plane to weight translucent combination of multiple faces seems to smooth it out a bit, and looks more interesting too.
# 19 Nineteen
practiced a bit for eulerroom set this weekend. more tomorrow…
worked a bit on a cut-and-project-inspired shader.

2D slice through 3D cubic honeycomb as nearby edges
the cut plane is white, colour based on direction from that plane in the invisible dimensions
image is pixelated due to computational constraints

as other image, but with 4D honeycomb
# 20 Twenty
I didn’t practice today… tomorrow morning need to set up obs and test etc, hopefully straightforward. i’m live at 11:15-11:30 UTC.
instead I added texture mapping to my cut-and-project experiment. also discovered my 16x16 grey+alpha logo image is smaller uncompressed as two pgm than as one png (even fed through pngcrush/optipng).
# 21 Twenty-One
played my eulerroom set. not sure if there were no streaming technical issues, i connected about 10mins before, and obs reported reconnection success at go live time, but viewer reported no live visible until i manually reconnected a few mins in. hopefully my local recording is fine and could replace archives if needed.
ported to C the multigrid algorithm from github.com/gglouser/cut-and-project-tiling (originally javascript and rust). i’m currently outputting svg, want to switch to opengl and add realtime animation. it is distracting when the nD rotation and translation makes polygons switch around in sudden jumps, but maybe i can configure things so that only happens for polygons outside the viewport… need to do more research on this.
# 22 Twenty-Two
# 22.1 Morning
figured out that what I want is not flat 2D rectangle moving around through nD space, but a curved 2D surface (like a ribbon) with a rectangle-parameterized window sliding along it.
this makes multigrid incompatible afaik, so back to less efficient implicit version - but given a sliding window, I only need to caclulate the leading edge each frame, instead of every pixel (the bulk can be reused by shifting the previous frame’s image sideways a bit), so computational cost is reduced ~1000x which makes it realtime feasible on my desktop.
didn’t code it completely yet, as full generality needs some kind of integral along an nD path while maintaining an orthogonal frame of reference at each step, which is tricky in a standalone fragment shader (I’m using Bonzomatic for prototyping), but early experiments are promising.
# 22.2 Afternoon

square grid in white outlines (with red/blue tint) on black at left hand side morphing to cubic grid on right hand side
here’s a screenshot from my netbook, which does about 20fps at 1024x128 resolution using Mesa software rendering, with the grid dimension set to 3D.
reminds me a little of a basic framework that could be elaborated into something like M C Escher’s Metamorphoses
3D is the lowest possible value; 5D is what I’m using on desktop because that decomposes nicely to 2D for image plus 3D for colour; while going higher doesn’t seem to add much more interesting variety.
# 22.3 Night
remembered a trick to embed system state in a few image pixels. doesn’t work at 1/2 or 1/4 pixelation, only at 1/8 - not sure why, probably texture filtering related (I have not yet found which gles2 extension enables texelFetch()).
now I can animate a ribbon sweep through space entirely in fragment shader. tested with android shader editor but should port to bonzomatic etc without much issue.
using gram schmidt matrix orthogonalisation to keep frame of reference consistent.
some rendering glitches occur (clipping), probably not too hard to fix…

# 23 Twenty-Three
no ‘#extension’ for texelFetch on gles2 afaict (EXT_gpu_shader4 is for desktop gl)
but ‘#version 300 es’ works fine on tablet for gles3, and that has texelFetch.
scrolling ribbon works at higher resolutions on tablet now (but maybe that was a different bug I fixed)
# 24 Twenty-Four
I reverted the vectorisation stuff I added to my music project, too non-portable (don’t like depending on gcc) for minimal gain (a few % cpu efficiency) and it makes the code more complicated.
thought about removing the tgmath dependency too, as that breaks build with tcc, but didn’t do the work yet. mainly will involve defining a bunch of macros to math() vs mathf() function calls depending on configured sample type.
tcc doesn’t support inline asm on arm, found and fixed a bug that wasn’t skipping my libc replacement when intended.
also found and fixed a couple of bugs with the play-all mode (it would play every other track starting from track 3).
tried my ribbon-through-nD grid shader on netbook with Mesa software rendering, about 2fps at tiny resolution. need to optimize.
# 25 Twenty-Five
day off from code
# 26 Twenty-Six
woke up early from dreams of code
had some ideas for an audio live coding system for classic Amiga, similar to OctaMED’s synth instruments but with variables / conditional / branch / loop constructs, plus synchronization with other audio channels (sleep/wake ideas)
had an idea for a sound to make in that hypothetical system, like noise morphing to a pitched drone.
# 27 Twenty-Seven
a bit of fiddling with glx, but did not achieve a/v sync with oss audio. did not try super hard, though.
switched to MINGW+Wine, got a rudimentary audio-synced video working using Windows API, after wasted lots of time with faulty Mesa swapinterval (with software rendering).
played a bit with bonzomatic, just small experiments, nothing finished..
# 28 Twenty-Eight
a bit of fiddling with bonzomatic, some textures based on difference between horizontal and vertical blur
# 29 Twenty-Nine
updated december adventure page on my website
# 30 Thirty
did some small updates to my audio transcoding and metadata tagging system
# 31 Thirty-One
ported an old Pd patch to Javascript