Adaptive super-sampling using distance estimate
By the Koebe 1/4 theorem, the distance estimate for the Mandelbrot set can be used for a colouring where every dark pixel is near the boundary and every pixel near the boundary is dark. Plain super-sampling (calculating several points for each output pixel) can be used to show finer details, but can be slow. Super-sampling for distance estimate colouring can be accelerated by only subdividing dark pixels, because light pixels are far from the boundary and would still be far from the boundary when subdivided.
Here's the core function of a small C99 renderer that uses this technique:
double cabs2(complex double z) {
return creal(z) * creal(z) + cimag(z) * cimag(z);
}
double colour(complex double c, double pixel_spacing, int maxiters, int depth) {
double er2 = 512 * 512;
complex double z = 0;
complex double dc = 0;
for (int i = 0; i < maxiters; ++i) {
dc = 2 * z * dc + 1;
z = z * z + c;
if (cabs2(z) > er2) {
double de = 2 * cabs(z) * log(cabs(z)) / (cabs(dc) * pixel_spacing);
if (de <= 4 && depth > 0) {
double p2 = pixel_spacing / 2;
double p4 = pixel_spacing / 4;
return 0.25 *
( colour(c + p4 + I * p4, p2, maxiters, depth - 1)
+ colour(c - p4 + I * p4, p2, maxiters, depth - 1)
+ colour(c + p4 - I * p4, p2, maxiters, depth - 1)
+ colour(c - p4 - I * p4, p2, maxiters, depth - 1)
);
} else {
return tanh(de);
}
}
}
return 0;
}If the distance estimate is small compared to the pixel size, the pixel is subdivided into 4 smaller subpixels, up to a maximum subdivision depth. In the worst case, where every pixel is subdivided all the way down, this needs more computation than plain supersampling due to the intervening levels, but for many locations the adaptive method eventually wins in terms of efficiency. The efficiency is related to the apparent fractal dimension - though in the limit the dimension of the boundary of the Mandelbrot set is known to be 2, most views rendered are not that dense.





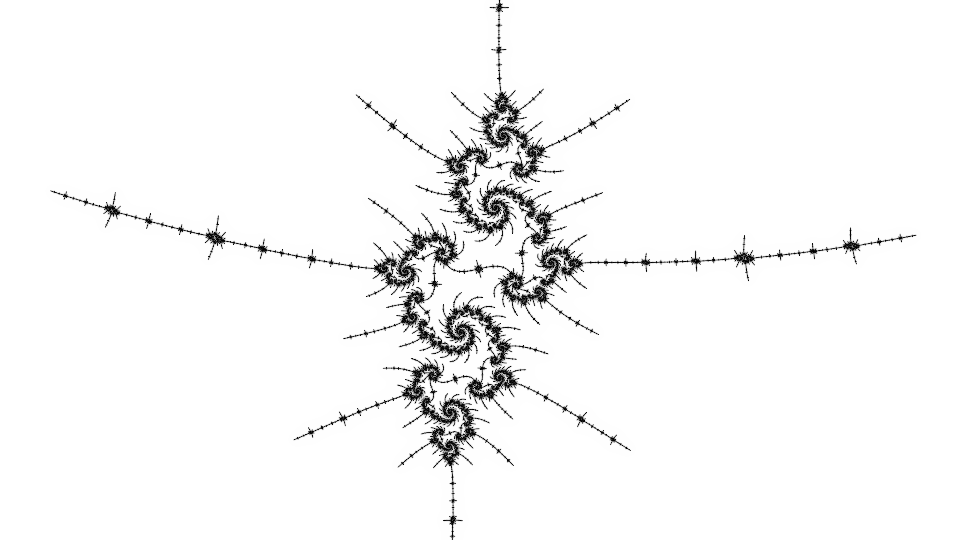
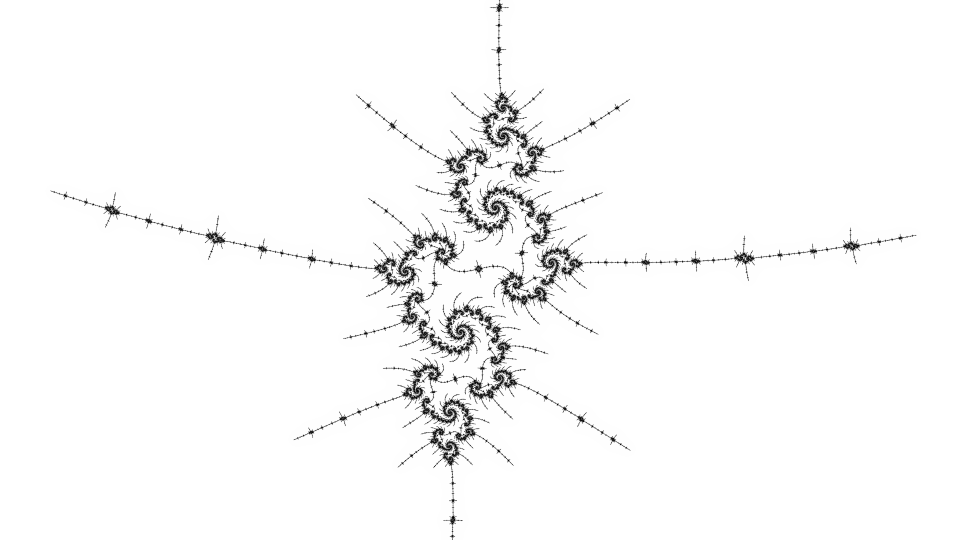
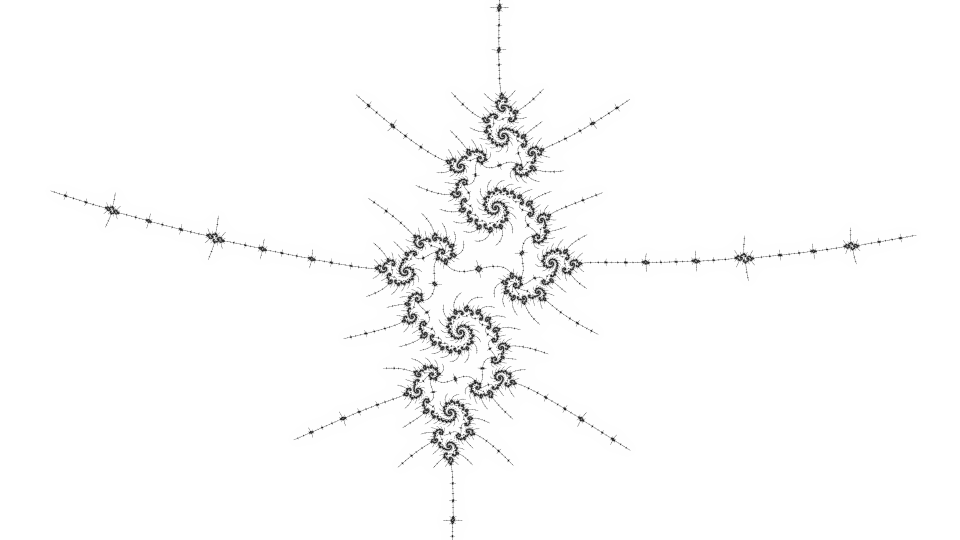
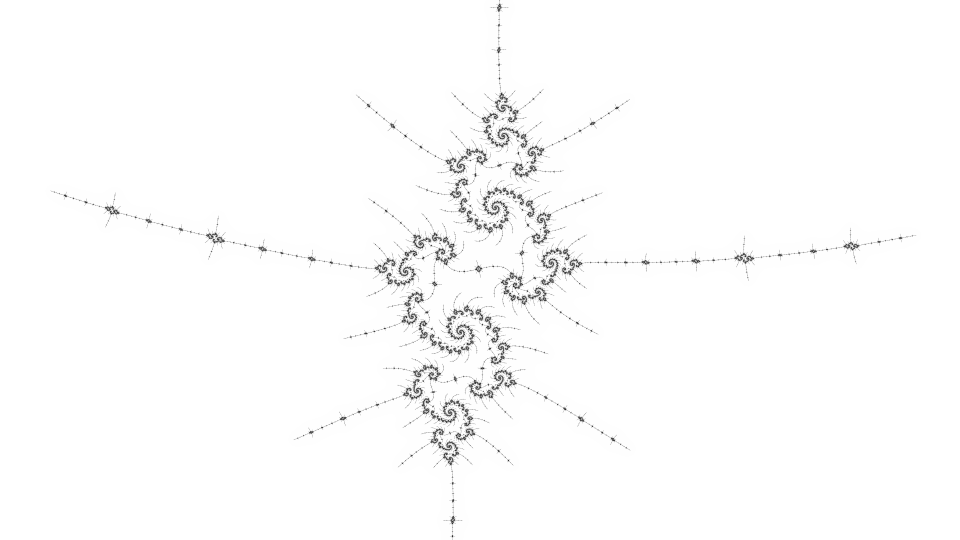
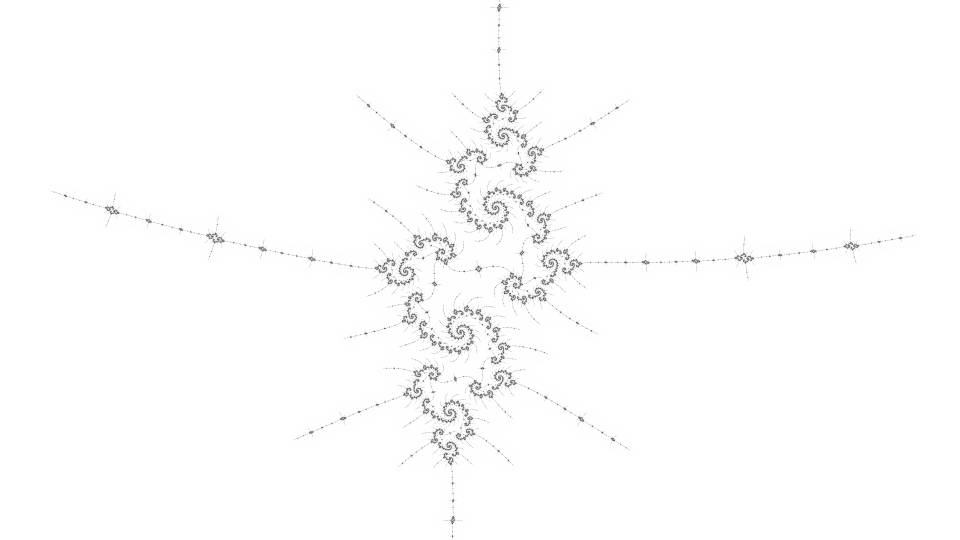
Here are some benchmarks, first for the sparse view:
| depth | samples per pixel | time |
|---|---|---|
| 0 | 100% | 0.440s |
| 1 | 133.92% | 0.664s |
| 2 | 228.73% | 1.304s |
| 3 | 493.53% | 3.180s |
| 4 | 1233.22% | 8.737s |
And for the dense view, which only beats plain supersampling at depth 3 or above:
| depth | samples per pixel | time |
|---|---|---|
| 0 | 100.00% | 17.153s |
| 1 | 431.31% | 1m18.861s |
| 2 | 1668.51% | 5m18.520s |
| 3 | 6282.81% | 20m53.466s |
| 4 | 23465.98% | 81m35.974s |
You can download the full source code. Exercise: extend the algorithm to use interior distance estimates.
EDIT here are the parameters used for the images:
for depth in 0 1 2 3 4
do
time ./adaptive-dem 960 540 \
-1.769384146357043e+00 4.230589061544685e-03 1.1169192421368613e-05 \
1000000 ${depth} > sparse-${depth}.pgm
done
for depth in 0 1 2 3 4
do
time ./adaptive-dem 960 540 \
-1.747370489 4.733564e-3 3e-7 \
1000000 ${depth} > dense-${depth}.pgm
done