| cm | hc |
|---|---|
| ClaudiusMaximus | _hc |
| Claude Heiland-Allen | Hans-Christoph Steiner |
| (here) | http://at.or.at/hans/ |
Thu Jul 15 2010 - Fri Jul 16 2010
First, read Hans-Christoph Steiner's Let's Make Libraries paper.
The Big Name Clash Problem | |||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
22:55cmhm, i just found a big potential issue around the [import] that i'm working on
22:57cmsuppose you have 3 projects, each with "projectN/main.pd" and "projectN/foo.pd_linux" - each project does [import foo], but (currently) the first "foo" loaded will be the only "foo" loaded
22:57cmthis wouldn't be such a problem, except for the splitting of multi-object libraries into single-object libraries
22:58cmwhich makes name clashes in the library namespace 10000x more likely
22:59cmso i think i'll need to add the full absolute pathname of the loaded library to pd's loadlist or whatever it's called
| Even worse, consider the following directory structure: /usr/lib/pd/extra/foo/foo.pd /usr/lib/pd/extra/foo/foo.pd_linux /home/user/project1/MAIN.pd /home/user/project1/foo.pd /home/user/project1/foo.pd_linux /home/user/project2/MAIN.pd /home/user/project2/foo.pd /home/user/project2/foo.pd_linux | ||||||||||||||||
Importing Libraries | |||||||||||||||||
23:38hcdo you know what other programming languages do with library nameclashes?
23:38hcit seems like it should just load the first 'foo' it finds in the canvas-local apth
23:39hcthen you could include a custom 'foo' in the project folder
23:47cmright,that's what it should do
23:48hcthis library stuff is pretty maddening
23:48cmbut, pd has a cache of loaded libraries already (so [expr] [expr] will only load expr.pd_linux once)
23:48hckeeping track of all the edge cases
23:48hcyeah, it'll need the fullpath cachecd
23:49cmthe one i know most about is Haskell
23:49cmin haskell you have "packages" which export "modules"
23:49cmsometimes more than one package exports the same module
23:49cmthis is generally frowned upon
23:49hcthe other thing to consider here is pd patches vs binaries
23:50cmbut GHC provides -XPackageImports, which lets you specify the package name in the import
| With the -XPackageImports flag, GHC allows import declarations to be qualified by the package name that the module is intended to be imported from. For example: import "network" Network.Socket would import the module Network.Socket from the package network (any version). This may be used to disambiguate an import when the same module is available from multiple packages, or is present in both the current package being built and an external package. Note: you probably don't need to use this feature, it was added mainly so that we can build backwards-compatible versions of packages when APIs change. It can lead to fragile dependencies in the common case: modules occasionally move from one package to another, rendering any package-qualified imports broken. | ||||||||||||||||
Binaries vs Abstractions | |||||||||||||||||
23:50hcand the load order
23:50hclike [expr] in one project loads pd/extra/expr.pd_linux, but then someone puts expr.pd into their project folder
23:50cmgenerally you specify the package dependencies at build time, instead of in the source code
23:50cmyes, that's a good point
23:50hcfor that project, [expr] should be the local expr.pd
23:50cmindeed
23:51hcright pd is whacked in that regard
23:51hcit searches first thru all paths for .pd_linux, etc. then finally for .pd
23:51cmthe way i envision it is: if you don't have [import foo], then [foo] will do a full filesystem search as if foo wasn't loaded
23:51cmahhh i forgot about that, it doesn't intermingle searching for binaries and pds?
23:52hcnope
23:52hcI think I documented that in my papre
23:52cmyes i've got it open now
23:52cmso i'll need to switch the the order for sane behaviour
23:53hcyeah
23:53cmfor x in path do for y in ext do tryload(x.y) done done
23:53hcthere was a discusion about it, I forget where, and miller agreed
23:53cmok
23:53hcyeah
23:53hcI think abstractions first too IMHO
23:53cmyes i think i agree on that
| Currently vanilla Pd does something like this: | ||||||||||||||||
Warnings, Errors, Strictness | |||||||||||||||||
23:56cmanother thing is warnings/errors/strictness
23:57cmlike [import foo foo] should give a warning, but [import vanilla] shouldn't give a warning (because i plan a -no-vanilla flag for people who like barebones)
23:58cmand warnings could be turned into errors with -strict-import
23:58hcrather than having a special case in [import] for vanilla, I think we should just make 'vanilla' a library
23:58hcthen have it loaded by default in the config
23:59cmthe problem comes from adding -strict-import
23:59hcthis is how it was done, kind of, in pd-anyhwere
23:59cmwhich would make it an error to use [foo] without [import somethingthatdefinesfoo]
00:00hcyes, I think it makes sense that a library name shouldn't be inherinet an objectname
00:00cminherinet?
00:01hcinherently
00:01hcsorry
| There needs to be a small set of reserved words which are in the global namespace and cannot be overridden. pd inlet outlet inlet~ outlet~ declare import | ||||||||||||||||
Unspecified Behavior | |||||||||||||||||
00:01cmanother thing i've been pondering - if you do [import Gem maxlib] [scale] - what happens?
00:02cmi think it's best to leave is "implementation defined, don't do that"
00:02hcwell, there needs to be an clearly defined order, either first wins or last wins
00:02cmwell, that constrains the implementation - which isn't good for development
00:02hcthe implemenetation of what/
00:03cm[import]
00:03cmand the whole namespace system
00:03hchow so?
00:03cmwhich is complicated enough as it is without having to impose an order
00:03cmthe point is, if you connect an object box to two things, it's implementation defined unless you use [trigger]
00:04cmwhich is fine, as trigger exists and documents the behaviour properly
00:04cmand with [import Gem maxlib] you could do [Gem/scale] and [maxlib/scale] to disambiguate
00:05cmto forbid [scale] on its own, even when its ambiguous, would require checking for ambiguity, which would be expensive
00:05cm*only when
00:05hcoh, I see
| In Pd whenever a message is initiated, the receiver may then send out further messages in turn, and the receivers of those messages can send yet others. So each message sets off a tree of consequent messages. This tree is executed in depth first fashion. For instance in the patch below: the order of arrival of messages is either A-B-C-D or A-C-D-B. The "C" message is not done until the "D" one is also, and the "A" is not done until all four are. It is indeterminate which of "B" or "C" is done first; this depends on what order you made the connections in (in Max, it's automatically sorted right to left). | ||||||||||||||||
Handling Ambiguity | |||||||||||||||||
00:06hcI just mean that if you have [import Gem myscalelib maxlib], then which [scale] should be a clearly defined rule
00:06hceither [scale] equals the first the claim the name or the most recently loaded to claim the name
00:10cmi disagree, because you can disambiguate at point of use, and if that gets too much you could make an abstraction scale.pd [import Gem][scale] - and abstractions should take precedence over loaded objects?
00:11cmthe point is, the implementation needs to be abstract, so it has room to maneuver if some other implementation is seen to be better in the future
00:15cmi worry somewhat about the efficiency of this actually - it could slow down loading of large patches :-/
00:15hchow can you disambiguate at the point of use?
00:15cmuse [Gem/scale] and [maxlib/scale]
00:15cminstead of the ambiguous [scale]
00:15hcright
00:15hcbut [scale] should be unambiguous as well
00:15cmwhy?
00:16cmit's clearly ambiguous
00:16hcbecause programming sucks with things are ambiguous
00:16cmprogramming sucks more when you get random things happen instead of warnings or errors
00:16hcalso
00:17hchow do other langauges handle this case?
00:17hcthere can be both a warning/error and a defined rule
00:17cmin Haskell, if you have module A(foo) and module B(foo), you can import A; import B - but when you try to use foo you get a compiler error
00:18hcthat seems like the best bet, and the warning would say which [scale] is active
| Foo.hs module Foo (quux) where quux = 1 Bar.hs module Bar (quux) where quux = 1 Baz.hs module Main (main) where import Foo import Bar main = print quux ambiguity error at point of use | ||||||||||||||||
Better Data Structures | |||||||||||||||||
00:18hchow about pythong?
00:18cmright, but checking for ambiguity isn't easy
00:18cmno clue
00:18cmat least with the current implementation, it would require O(number of objects in all libraries)
00:19hchow are you checking for duplicates now?
00:19cmi'm not
00:19hcah
00:19hcwell, it seems like something to deal with later...
00:19hcbut it should be dealt with...
00:20cmbut seeing as library/object is stored as a method in library's objectmaker
00:20hcotherwise you rely on the user knowing that Gem has a [scale] when they want to use maxlib's scale in a Gem patch
00:21cmthe standard solution would be to loop through the imported libraries' objectmakers' method tables and count the number of matches
00:21hcit seems like it should cache the whole potential tree as it builds it
00:22cmhm, you mean [import foo] checks for clashes with vanilla, then [import bar] checks for clashes with foo and/or vanilla?
00:22hcyeah something like that
00:23cmthat could work, but if you have N libraries each with M objects, the time for that would be quite long, so maybe there should be an option to enable/disable that check
00:24cmthe time would be 0*M + 1*M + 2M*M + 3M*M + 4M +...+ N*M
00:24cmoops
00:24cmthe time would be 0*M + 1*M + 2M*M + 3M*M + 4M +...+ NM*M
00:26cmoops, got that wrong as well
00:27cmbut i think it works out as O((MN)^2), which is O((number of objects)^2)
00:27cmwhich is unacceptable
00:27cmit could be reduced to O(n log n) by sorting on object name
00:28cmwhich shouldn't be too hard
00:28cm:)
00:32cmactually i think [foo] is O(number of objects) if foo exists
00:32cmin current vanilla Pd
00:32cmwhen it could be O(log (number of objects) ) using the sorting trick
00:33cmbut implementing a balanced tree in C isn't my idea of a good time
00:34cmmaybe it would work to use realloc and qsort and binary search
00:35cmwhich would speed up objects with lots of methods too
00:37hcit seems that data structures will make a big difference here... but yeah, not so fun to do in C
00:37cmafaik the method table in each class is an array, which could be sorted with qsort
00:39cmqsort() is pretty fast, in one haskell project it was faster to export my lists to 2 arrays (one with key/index and the other with value), run qsort() on the key/index array, import back into haskell, and lookup each index in the value array
00:39cm..than to use the haskell list sort
00:40cm(i couldn't sort the value array directly for some reason, probably due to it containing functions that couldn't be marshalled, or maybe i was too lazy to write a Storable instance)
00:43cmi think the first priority is getting to the state where i can [import Gem maxlib] and use [Gem/scale] [maxlib/scale] [scale] (and get a random scale for the last one), before adding features
00:43cmfeatures like speed
00:43hcyeah
| m_imp.h m_class.c Asymptotic complexities of container data structures:
A map can be implemented as a sorted array: | ||||||||||||||||
Early Save Hook | |||||||||||||||||
00:44cmthe other thing is that [import] needs to "float up" to the top of the patch, like [declare] does
00:44cmotherwise if you edit the [import foo], it moves to the bottom of the patch and breaks everything
00:44cmor if you delete it accidentally and recreate it
00:45hc[import] and [declare] do that by adding their info to the #X declare line at the top of the patch
00:46hccheck g_canvas.c
00:46cmok
00:46hcIIRC, its a hook to the save method that ensures the #X declare lines are always written first in the file
00:47hcw00t, just reduced the patch tracker from 4 to 3 paages!
00:47cmcool
00:47hchopefully miller does a lot more...
| g_canvas.c g_readwrite.c | ||||||||||||||||
Controversial Indirection | |||||||||||||||||
00:48cmmy changes to m_pd.h will be controversial, i hope miller doesn't object to that...
00:48cm#define pd_objectmaker (*pd_objectmaker2) /* this is the big one */
00:48hcit would probably be good to avoid some of that
00:49hcas much as possible basically
00:50cmwell, that was the least invasive i could make it
00:54cmthe reason for that pd_objectmaker change, is that it's typedmess() that checks if the target for the message == pd_objectmaker, and if so does something completely different
00:55cmand that function is hella long and complicated
00:55cmso i thought it would just be easier if i switch the pd_objectmaker to whichever objectmaker i want to make objects with before calling typedmess()
00:56cmand switch it back afterwards
00:56cmbut that doesn't work, because pd_objectmaker is t_pd, which is just a pointer, so i can't store the extra info that the other objectmaker needs
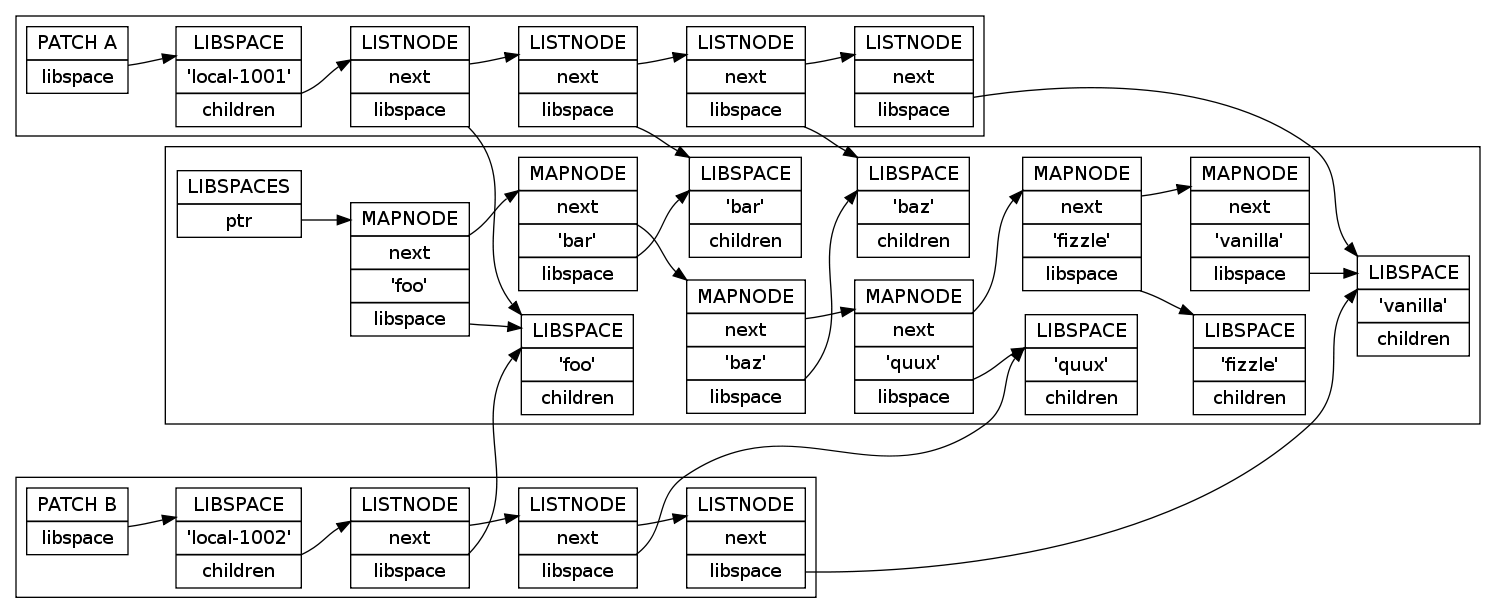
00:57cmmy objectmakers are approximatelt: struct { t_pd pd; t_symbol *name; t_listnode *children; }
00:58cmas in this diagram: 2010-07-16_puredata_libspace_structs.png
00:58cmwhere patch A would have [import foo bar baz] and patch B would have [import foo quux]
00:58cmLIBSPACE is an objectmaker, basically
| | ||||||||||||||||
Exporting Libraries | |||||||||||||||||
01:07cmthe other idea i had is [export], did you have any thoughts on that?
01:07hcthat sounds scary
01:07hc;)
01:08cm19:17cmthe idea is that a patch like [import foo bar baz] [export quux] will enable subsequently loaded patches to [import quux] and get all of 'foo bar baz'
01:08cm19:17cmand of course [export $0-mamamama] would work
01:08cm19:18cmnot sure what should happen if [export] is given an already defined libspace
01:08cm19:21hcthat sounds cool but tricky to get right
01:08cm19:25cmit isn't that tricky to implement, it would just be something like "libspace_add_to_global_list( libspace_add_child( libspace_new(gensym("quux")), canvas_local_libspace(canvas_getcurrent()) ))"
01:08cm19:25cmbut the edge cases like conflicting exports and deciding when to deallocate stuff (if ever) wouldn't be fun
01:08cm19:25hcyeah, it is all about the edge cases...
01:08cmoops, that was longer than i expected
01:10hcit seems to me there needs to be three levels of import: global project-level and patch local
01:10hcdeclare does project level, kind of
01:10hcI think we these three levels, you wouldn't need [export]
01:10cmright, [export] is designed to fill the project-level gap
01:11cmso the top-level patch does [import foo bar baz] [export project], and the rest can do [import project]
01:11hcI think [import] should really be patch-local, but something like [declare -path] makes sense to have it project-wide so that you can set a special 'extra' dir for the whole project
01:11cmit is
01:12hcI don't really see having libraries loaded on a project levle;
01:12cmah, i forgot all about paths
01:12cmthere are arguments both ways
01:12cm1. you have all the information about all the imports of the project in one place
01:13cm2. but then parts of the project don't have specific imports, which makes it hard to reuse them outside the project
01:14hcdo you know about these wiki pages:
01:14hchttp://puredata.info/dev/PdNamespaces
01:14cmi haven't checked the wiki
01:14cmyes
01:14hchttp://puredata.info/dev/PdSearchPath
01:14cm*yet
01:15cmah, they look very handy
01:15cmthanks
01:15hcplease add/correct as you see fit
01:16cmso far i'm targetting 1+2+6 on the wishlist afaict
01:17hc[classpath] is quite easy AFAIK
01:19cmcanvas-local is per patch as far as i can work out
01:19cmsubpatches are in the same patch, abstractions aren't
01:19hcyeah
01:19cmi'm not sure if this is always the case though
01:19hcit should be
01:19hcexcept for [switch~]
01:20cmall the canvas-local stuff i've been working on has been with t_canvas_environment
01:22cmand i really hope that's always per file, because if subpatches get their own environment sometimes (switch~ or gop or user changing font size or something else random) it would cause havoc
|
THIS SPACE INTENTIONALLY LEFT BLANK
| ||||||||||||||||
The End | |||||||||||||||||
{kind=link}